就在今早9点,特斯拉举行办了一场让汽车圈和科技圈都为之震动的活动——“AI DAY”(人工智能日)。活动中,特斯拉讲解了其在自动驾驶领域的最新进展,并发布了由自主研发芯片提供算力的超级计算机Dojo以及一台人形机器人。为自动驾驶研发超级计算机?这个相信很多人都闻所未闻。废话不多说,我们接下来就看看会上曝了哪些猛料吧!

(注:由于本次活动所涉及的知识过于硬核,编辑只能通过自身相对有限的专业知识尝试进行解读,如有不对的地方,还请读者指出,我会第一时间更正。)
■30秒速读全文:
1:特斯拉革新了Autopilot运算单元的算法,使其可以像人类一样通过视觉观察路况,并通过神经网络运算单元像人脑一样判断危险因素,而无需雷达、激光等感知元件;
2:为了让Autopilot能够准确识别道路的元素,特斯拉设计了一台名叫Dojo的神经网络超级计算机,它的性能超越了目前世界排名第一的超算;
3:作为活动结尾的彩蛋,特斯拉还发布了一款人形机器人,用来替代人类在危险环境下工作以及执行营救任务。
■基于纯视觉的FSD究竟如何实现?

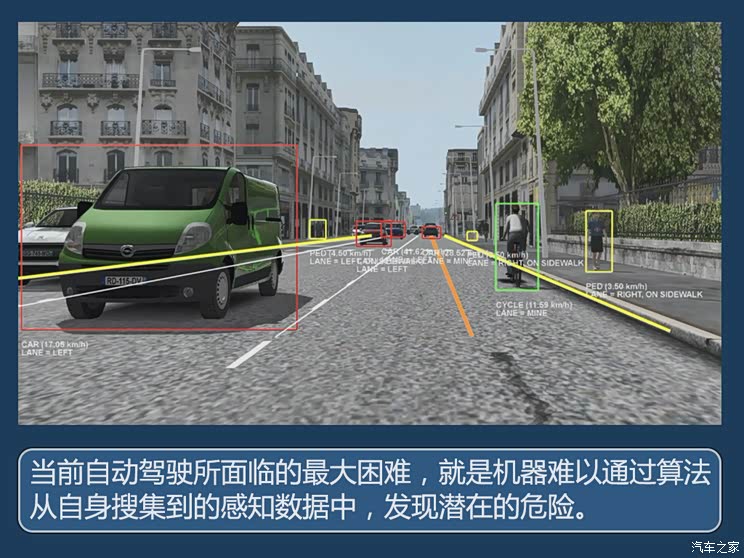
既然需要通过视觉方式实现自动驾驶,那么首先需要给车辆安上眼睛,而这个眼睛就是摄像头。摄像头的工作方式其实与人眼比较类似,就是通过收集光线强度与色彩信息,然后发送给类似人脑的AI运算单元进行分析,从而判断面前的物体究竟是什么。
尽管目前业界通过摄像头进行场景元素识别的技术已十分常见,但是大家的普遍做法都是将摄像头采集的照片以单张图片作为单元进行分析。这样带来的问题是单一的图片属于2D图像,所展现的物体信息较为局限,我们很难通过图片去感知图像中物体的真实形状以及运动速度等信息。

面对这一问题,业界有一种主流做法是通过激光雷达去感知物体的形状,用毫米波雷达去感知物体的运动速度以及轨迹,将这些信息匹配合成,再交给车辆的自动驾驶运算系统进行决策。

而目前,特斯拉正在过渡到纯视觉的自动驾驶感知路线,如今在美国生产的特斯拉车型已经开始抛弃雷达等其他感知元件。特斯拉这么做的底气是它抛弃了传统以单张图片作为场景感知的最小单元,而是进化到了通过连续的视频图像对场景进行感知。
通过视频图像对场景进行感知有几个好处,首先,统一了信息输入方式,避免了因为雷达、摄像头等不同感知元件所提供的相对分立的数据,而增加算法的复杂度;其次,特斯拉可以通过视频的方式掌握交通参与者当前的运动方向以及速度,而不需要借助雷达;第三点,也是很重要的一点就是特斯拉能够通过视频来构建车辆周围的3D场景,有了道路环境的立体信息,将能够让车辆更准确的识别环境中的危险元素。

尽管通过视频图像对场景进行感知有不少好处,但想要做好这项技术并不容易,主要的难点是如何让Autopilot系统对所有接触到的场景都能有一个准确的判断。为此,特斯拉专门设计了一台超级计算机来训练算法。
■这次活动的重点:Dojo超算正式发布

当您了解了Dojo的原意之后,就不难理解特斯拉为何要将自主研发的超级计算机命名为Dojo了,因为它正是特斯拉自动驾驶技术的“修行”之地。那么,特斯拉究竟是如何通过一台超级计算机来“修行”自动驾驶技术的呢?想要明白这个问题,我们需要先从特斯拉自动驾驶技术发展说起。
还记得几年前在美国发生的第一起特斯拉Autopilot 命案吗?当时一辆特斯拉Model S(参数|询价)开启了Autopilot,由于感知系统并未发现前方横向行驶的半挂卡车而与其发生了相撞,导致驾驶员当场死亡。事后调查显示,这是由于特斯拉的视觉感知系统并未识别到前方硕大的半挂卡车,而是把车上的白色货厢当成了天上的白云,致使与其相撞。

为什么特斯拉的感知系统会把一辆半挂卡车的侧身识别成白云呢?其实原因就在于Autopilot系统对于一个横向行驶的半挂卡车的特征并不熟悉。那么解决问题的办法就是通过不断的训练Autopilot的算法,从而避免再在类似的场景下出现误判。

特斯拉会从旗下车型的摄像头中搜集规模庞大的道路行驶视频画面,然后提供给Dojo进行自主学习。Dojo会把画面中许多类似卡车、行人甚至动物等道路中经常出现的危险元素进行标记,并将这些事物的特征以及应对措施写入Autopilot的程序中,然后特斯拉再通过OTA的方式,将最新的Autopilot程序推送给车辆,使这些车辆对面前的事物有一个更准确的认知,从而更好的对风险进行预判,避免类似将货车识别成白云的事故再次发生。
 查看同类文章:电动车新闻企业动向新技术更多精彩内容:车市消费洞察汽车之家新能源频道-前沿精准 全面深度
查看同类文章:电动车新闻企业动向新技术更多精彩内容:车市消费洞察汽车之家新能源频道-前沿精准 全面深度





- 奥迪RS3 Saloon和Rs3 LMS赛车在巴黎透露
- 2012年SEMA展览的女士
- 标致308的评论,价格和规格
- 大众希望振兴高尔夫销售
- 2019 Hyundai Santa Fe取笑…将于今年晚些时候在这里推出
- 厦门市进一步提升网约车合规化水平
- 保时捷Taycan跨界车确认
- 热门新的Alfa Romeo 4C Quadrifoglio Verde Spied Testing
- 这款一次性迈凯轮675LT拥有战斗机内饰
- 传闻:保时捷在电动SUV上工作
- Quans E-SportLimousine概念批准公共道路
- Samson SwitchBlade飞行车准备2018年推出
- 到2030号道路:电动汽车充电会花费多少消费者?
- “现在是赶上我们的高科技汽车的道路规则的时候了”
- 特斯拉骨头的Icon Helios流线型车是我们不想从中醒来的梦想
-
续航无焦虑,安全无死角,东风Honda让严寒无忧

2024-02-07 18:23:53
-
金龙献岁燃擎启新,思域归家红运盈门

2024-02-02 12:02:14
-
优雅亮相2024星月盛典,捷途旅行者荣获“年度最佳明星旅行伙伴”奖项

2024-02-01 12:20:41
-
汽车内卷时代,思域归来仍是热销

2024-01-30 12:31:10
-
奇瑞集团斩获中国汽车风云盛典四项大奖,中国力量,实至名归

2024-01-29 16:00:26
- 2017 BMW X5分享7系列的内限
- 代换燃料罚款750万美元
- Aston Martin vanquish碳版透露
- Fackifteded奥迪SQ2推出了新鲜的造型和新技术
- 美国机构抛28页报告质疑FF公司造车能力
- “汽车制造商没有忘记如何让我们咧嘴笑转”
- Dacia在2013年引领欧洲汽车市场增长
- WRC 2018:葡萄牙拉力赛的胜利使蒂埃里·诺伊维尔(Thierry Neuville)冠军遥遥领先
- 在豪华中大型车市场站稳脚跟,红旗H9会动谁的蛋糕?
- Top-Spec Mitsubishi Shogun SG5透露
- 2013年斯巴鲁XV Crosstrek驱动器评论
- 雪铁龙C5将以未来派风格重生
- 鹅口虫 - 非常普通的现代I20,假日汽车障碍
- 货舱是2012 Toyota Prius v上的王者
- 保险业呼吁政府清楚地定义自治车